Archivo
Vatuta, a RAG for managers
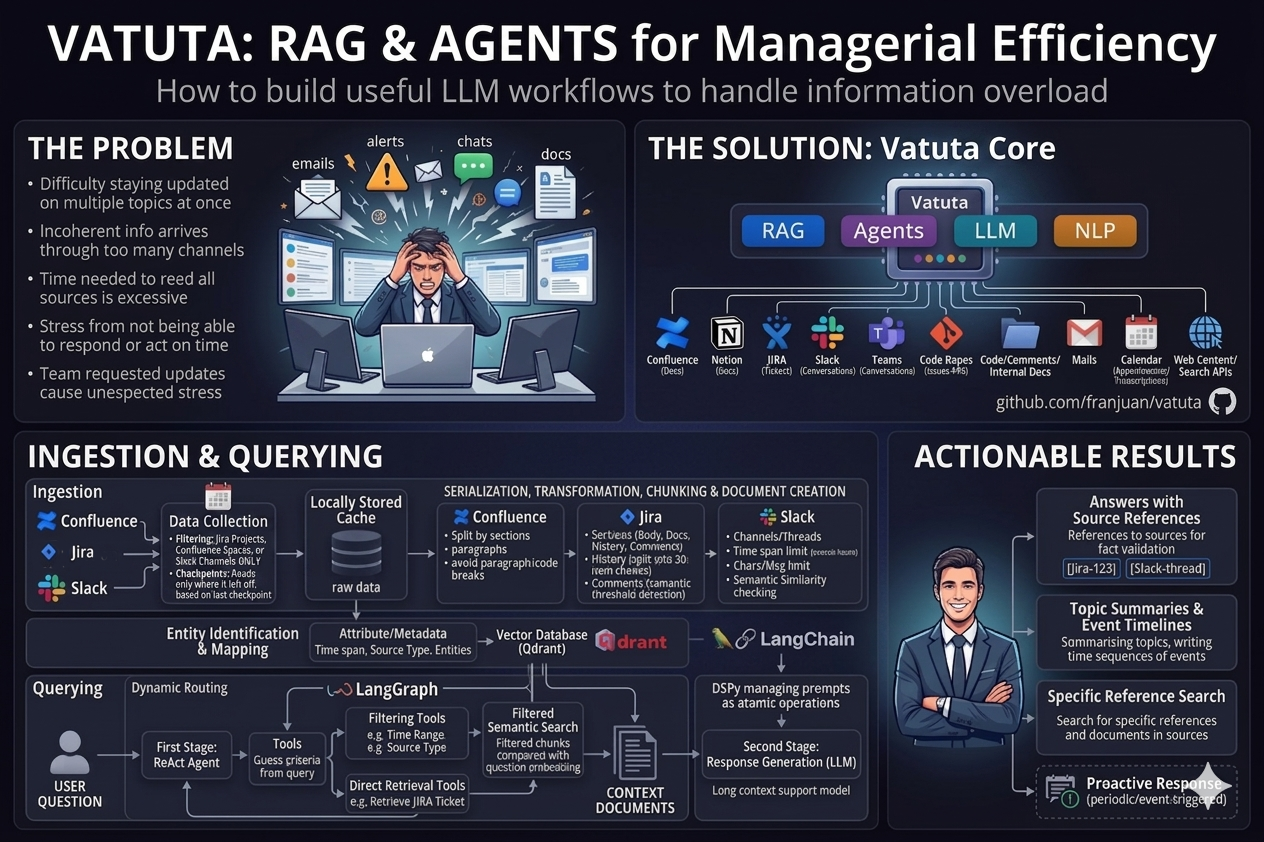
A problem
After so many years working as a manager, I had the feeling that one of the most stressful tasks to accomplish is to be aware of all the information and being able to act and respond with the right, proper, and updated data:
- When you are focused on one topic, it is very difficult to stay updated on the other ones.
- The information arrives and flows through so many different channels that it is very difficult to follow all of them. It may also be incoherent across them.
- The time needed to read all sources and be able to interpret all of them would consume all your work time, forcing you to do actual work in overtime, when the sources’ activity decreases.
- The stress of feeling that you would not be able to respond or act when something happens because you are not updated enough.
- The stress you, as a manager, cause to the team when you request updates and reports at an unexpected time or with very high frequency.
An idea
AI and NLP, especially LLMs, helped some time ago to mitigate this manager stress in meetings by transcribing and summarizing, features now common in many call applications. We can apply the same technologies to reduce stress and help manage information flows for managers.
We can use a common RAG architecture to help managers have higher confidence that relevant information can be retrieved when needed. The sources are collected and processed into a vector database where the information is available for queries. When performing a query, the RAG system collects the related documents for the query and uses them as part of the context for the LLM to elaborate a response.
Typical sources of information are:
- Documentation like content in Confluence, Notion
- Tickets from JIRA or similar systems
- Conversations from chat systems like Slack or Teams
- Issues and pull requests from code repositories
- The code itself, its comments, and internal documentation
- Emails
- Calendar events, meeting notes, and transcripts
- Web content and search API responses
Although the most common use case is the typical question-answering use case based on RAG systems, it may also be used to summarize topics, write time sequences of events, or search for specific references and documents in sources. Source citations can help mitigate hallucinations and make answers auditable, although they do not fully guarantee correctness.
Although the current first implementation of the system is completely reactive, as it responds when invoked with a question, it can be improved to act proactively when an event is triggered or periodically.
The implementation
The solution is implemented in Python. The RAG behavior is based on LangChain and LangGraph, as they are great frameworks for managing the flow of the solution. But the invocation of the prompts is based on DSPy, as it allows us to manage those prompts as atomic operations, which is very useful to optimize and reuse them. The vector DB is Qdrant, as it is a great solution, balancing performance and functionality. You can find the whole stack of libraries and components used here.
An ecosystem of common tools and libraries for Python is used, like Poetry for dependency management, pre-commit scripts for compliance assurance, GitHub Actions for CI tasks, Ruff for code formatting, mypy for static checking, pytest for unit testing, Typer and Rich for the command console, Prometheus for observability, just for developer UX comfort, Hugging Face libraries for diverse NLP and transformers tasks, Bandit, Semgrep, and pip-audit for security management…
The UX is based on a command-line client that supports both the commands for ingestion of sources and asking questions. It can be easily extended to other interfaces, like a chatbot one. The whole parameterization is based on config files, so the command arguments are limited to what is strictly necessary. It is intended to make it easy to check and validate the project as the PoC it is.
Source ingestion
The first step before any question or command can be requested is to ingest data from sources into the vector database. The solution collects raw data — messages, documents, tickets… — from the source and stores it locally. This data is stored in a cache, as the raw data may be processed several times. If the processing flow of data changes, evolves, or is refactored in some way, the data does not need to be collected again. The data collection is a batch process. It is collected from the source using some filtering criteria — channels, projects, spaces… — and restricted to a temporal range. This range starts from the last time data was collected and goes to the current moment in time, in an incremental manner.
The data, depending on its nature, must be serialized, transformed, and split into chunks and documents. The data is processed sequentially to be split and joined into chunks. A chunk is the minimal document entity in the vector database. When creating the chunks, some attributes are extracted from the content and added to the chunk metadata. This metadata is used to filter and restrict the search in the vector database to constrain it to a narrower scope than only using the embedding. The chunk and its embedding are stored in the Qdrant vector database with their attributes.
These attributes can be the time span of the chunk, so we can limit the search to a specific period, or the kind of source, so we can limit the search to this source type, for example. Additionally, entities like users/actors are also identified and added as attributes. Those entities are matched across different sources by using common linkable data, so their identity is preserved across different sources.
Although the hierarchy of chunks into documents can be quite flexible, allowing more complex structures, the current implementation just groups the chunks into a single document, and only chunk-based search is used.
Every source type requires a different strategy depending on its nature and content structure:
Confluence articles are split by sections into chunks. When the content of sections is too big, it is split into smaller chunks with a maximum size, trying to avoid dividing paragraphs or code sections.
JIRA tickets are split into chunks based on the different sections and content a ticket can have. The whole body, description, and main attributes are the first chunk. The relationship with other tickets is a second one. The history of the ticket is a third one, but it is split into several chunks of 20 items each. Finally, the comments of the ticket become chunks, keeping a maximum size in characters and comments per chunk, but the chunk is also split if the semantic similarity of the current comment compared to the previous one is below some threshold, to detect a change of topic in comment threads.
The Slack source divides the different channels and the threads inside them into sequences processed independently. Every conversation is split into chunks in several ways at the same time: messages within a time span are kept in a single chunk — several hours — but they can be split into several chunks when a character or message limit is reached. Finally, to keep the same topic in every chunk, there is a semantic similarity check, so messages are kept in different chunks when their similarity is below some threshold.
Questioning
When asking a question, a dynamic routing strategy is put in place. The answer is processed in two stages managed with LangGraph.
The first stage takes care of collecting the right data for answering the question. In order to do that, this stage behaves following the ReAct — Reason Act — pattern with several tools available. These tools limit, restrict, or complement the query so the embedding is compared against an already filtered set. The agent interprets the user’s query and chooses the proper tools to set this filtering.
Examples of tools or filtering criteria are the time range of the source, i.e., “from the last month”, or the type of source, i.e., “from JIRA tickets”. If the agent, following system prompt instructions, detects a reference to some time span or to a source type in the query, it will call the related tools to create filtering criteria over the chunks metadata in the vector database. Then, a similarity semantic search, based on embeddings, is performed on the Qdrant vector database, but against the subset of filtered chunks. Therefore, the subset of chunks compared with the embedding of the question is smartly restricted by the query before comparison. From all the compared documents, the most similar k are collected, k being a command-line parameter.
Other tools allow the system not to filter, but to add and collect documents or data directly into the context. For example, if a JIRA ticket reference is detected in the query, the content of the ticket is retrieved and added to the context documents for the next stage.
This mechanism allows the system to point to the right documents for answering the query, improving the correctness and accuracy of responses. This agentic routing provides flexibility, and it is more useful when the query requires interpretation or multi-step retrieval. But deterministic extraction may be preferred for obvious constraints such as dates, source types, ticket IDs, and user mentions.
The second stage takes care of answering the query by using an LLM prompt including the documents collected in the previous stage, with the query and a proper system prompt.
Flags in the command line allow showing the retrieved documents, the applied filtering criteria, and an execution trace of the routing stage: selected tools, tool inputs, intermediate results, and final retrieval decisions.
All prompts are based on the DSPy library, which helps to manage them programmatically, as an API call. DSPy can be used to optimize the prompting strategy by defining the program structure, representative examples, and evaluation metrics. This makes prompt optimization more systematic than manually editing prompt strings.
The challenges
Sources nature
Sources have a different nature, completely different from each other. The strategy used to collect the data and to process it into chunks is quite different. Every integration pattern based on APIs, streams, or exported documents is an integration use case that needs independent work. There is no standard or service, as far as I know, that aggregates different sources into a single common pattern ready for ingestion.
Confluence and JIRA sources are comparatively easier to model because they expose clearer document-like entities, as the document concept is clearly defined and split into sections or parts that can be ingested as chunks.
But Slack sources do not have such a concept of a document. Even when channels and threads can be considered documents, they extend over time, and the topics are so different and changing that it is quite difficult to isolate them into chunks or documents.
The strategy followed is to group messages in the same channel or threads until some inactivity is found. After 4 hours of inactivity, we consider the topic is no longer related between the last and the new message. This is a heuristic for simplification, and it may be improved. Even when the inactivity threshold is not reached, when the chunk size in characters or messages reaches a limit, the chunk is split to avoid chunks that are too big. Finally, even when the size or time limit is not reached, every new message embedding is compared using cosine similarity with the last one. If the similarity is below a threshold limit, we can assume the topics in both messages are very different, and the chunk should be split. For this purpose, the embedding algorithm used is multilingual-e5-small, which is extremely light and fast to boost the ingestion process.
Semantics
As the chunk is located by its embedding, in some way, this embedding stands for its meaning. If we choose very small chunks, their embeddings don’t capture the real essence and meaning of the context of the sources, and they become useless. If we choose very big ones, their embeddings cover too broad and superficial meanings, which are also useless because they would be much less specific, and the right chunks for the query would not be selected.
The solution is part of the previous section. The right chunking of the source so its contents capture the right topic or meaning is essential, but so is the embedding algorithm that converts the chunk to a vector. The algorithm multilingual-e5-small is used because of its performance and resource usage. Embedding algorithms have a maximum token length. The solution chunks the content of the source, keeping in mind this limit.
Batching vs streaming
Collecting the source data in batches is easier, and its processing is even easier as you have the whole content to perform the chunking. But, in order to be more proactive instead of reactive, data should be ingested in real time. This implies a lot of complexities not considered in batching, like chunks that are not completely closed or that are rewritten once a new message belonging to them comes to the system. Additionally, batch collection through APIs is easier, and sometimes the only choice, compared to pulling streams or events.ts.
Embeddings are not enough
Embeddings are essential for RAG systems, as they provide the semantic classification for collecting the documents. But their results may be difficult to tune, and adding other strategies helps to improve the results significantly.
The first strategy is to limit the universe of chunks to those that we can be more sure are related to the query. The attributes, metadata, or identities extracted during ingestion are used to filter the chunks to compare for embedding similarity. The right selection of the filtering will constrain the set of chunks to those that belong to the subject or matter of the query.
The problem is that such a filtering criterion cannot be guessed in advance; it depends completely on the query. The filtering has to be guessed from the query. A ReAct agent calculates it from a query in the first stage and provides the subset of documents to be included in the context for RAG. The agent may also collect documents by other means, like the whole JIRA document or by pulling data from APIs.
This is the way it is implemented right now, but it can still be improved. We went for the filtering approach to improve the embedding-comparison-only strategy. But filtering of chunks may also be inexact or faulty. We are considering that all attribute or identity extraction works precisely, and no document is discarded by mistake. That is not the case. If the right document is filtered by mistake, the answer will never be accurate and complete.
The idea is not to filter out chunks, but to re-rank them by using the criteria. Those chunks matching the criteria will have a better score, so they will be reordered to the top. If a chunk was previously discarded because it did not match a small part of the filter, now it will still be scored. Then a top-k truncation is performed, but we are better ensuring that the chunks are relevant to the query.
Model selection
Depending on the task, the right LLM model may be different. Even when a model may be effective for a task, it may not be efficient due to its cost or resource usage.
For the first stage of the querying, the one in charge of identifying the filtering criteria of chunks and retrieving the related documents, the model must support tools, but it may not need reasoning or great performance. Additionally, because the ReAct pattern is a model that is called many times per query with short prompts, a big context size is not needed.
The second stage does not require tooling. Its main responsibility is to synthesize an answer from the retrieved context. However, depending on the question, this stage may still require reasoning, as it may significantly improve complex responses. In this case, as the documents are included in the prompt, models with long context support and good performance are needed.
The solution supports configuring the selection of the model from the provider’s catalog. DSPy and LangChain support many providers, so model switching should be quite easy and direct.
To-dos and improvements
The current status of the project may be considered a proof of concept. Some ideas to improve in the future and continue exploring are the following:
Embeddings are calculated with the algorithm all-MiniLM-L6-v2. Although it is quite efficient and has low resource consumption, it is constrained to 256 tokens. The current solution doesn’t control the chunk size according to this limit, and that means chunks are truncated for embedding calculation. This must be fixed with a proper algorithm or chunk size control.(Embedding replaced bymultilingual-e5-small. Mechanism for truncation detection added)- Sources are ingested in batches scheduled periodically and on demand. This simplifies the ingestion and processing of sources, but prevents any proactive or real-time action. Pushing of sources or streaming may be a very interesting feature.
- Responses right now do not include citations, becoming more vulnerable to hallucinations, or at least less auditable. Enabling direct linking to sources and forcing it in the prompt would be very useful and helpful for validation, too.
- Chunks are filtered through metadata and attributes before embedding comparison. Wrong or missing attribute extraction during ingestion will filter potentially relevant documents. By reranking instead of filtering those chunks, although ordered at a lower level, they may still be included in context.
- The current Qdrant search is based on filtering by metadata and embedding comparison. Qdrant can support hybrid retrieval by combining dense semantic vectors with sparse lexical representations and metadata filtering. This would help with exact terms, ticket IDs, names, acronyms, and other cases where dense embeddings alone are weak.
- The current RAG solution is quite useful for specific, detailed, and accurate questions. When answering summaries, stats, or general topics, this solution doesn’t work well or requires a very big context, with too many chunks in it. A solution like GraphRAG to support general topics, relations between elements, summaries, or stats would be a very interesting exercise.
- Quite related to the previous point, an unsupervised topic classifier would be useful to classify questions and chunks, and filter or rerank by their topic.
- No validation was done at all 😓, and unit testing requires a lot of improvement.
- Prompting is supported by the DSPy library. Prompt optimization can be performed automatically with DSPy by adding metrics and samples for optimization.
- The current solution is totally reactive; it requires the user to ask a question. It would be quite interesting to respond to triggers or be scheduled in some way for proactive behaviour. This is quite related to the sources being ingested in real time.
- There is no security analysis in the solution, beyond the dependency scan with pip-audit or the SAST analysis with Bandit or Semgrep. A more detailed security analysis would be needed based on the OWASP Top 10 for LLM / GenAI, for instance.
- Several LLM models, Anthropic and Gemini ones, were used, but other LLMs may be tested when some validation is ready.
Conclusions
These are the main insights I personally get from this experience:
- Embeddings are not enough. Metadata, identity extraction, lexical search, and reranking can significantly improve retrieval, but hard filtering should be applied carefully because it may remove relevant evidence.
- Dynamic routing is a great pattern because of its flexibility to filter, rerank, and select the right documents for the context.
- Very useful for specific questions about concrete topics or events, but weak for global reporting, aggregate metrics, and broad summaries unless combined with precomputed summaries, structured analytics, topic models, or GraphRAG-like approaches.
- Source integrations are complex and highly source-dependent. Each source has its own structure, API limitations, semantics, and ingestion challenges.
- Different operations require different models and embeddings. Combining several models with different strengths, costs, and drawbacks is important to build a more effective and efficient system.
